
puppeteer爬虫豆瓣电影
2019-10-24
原因
今天朋友给了我一段类似
[
{
movieID: 20191019000001,
movieName: "极限逃生",
},
{
movieID: 20191019000002,
movieName: "我们",
},
{
movieID: 20191019000003,
movieName: "在黑暗中讲述的恐怖故事",
},
{
movieID: 20191019000004,
movieName: "小丑回魂2",
},
{
movieID: 20191017000004,
movieName: "坏种",
},
........
这样的电影数据,大概有个2k多条,让我帮他找到所有电影海报图片。
当然第一反应就是豆瓣API。通过搜索接口把所有的图片URL找翻来找去发现豆瓣官方的api已经关闭了,停止注册了。试了试网上的其他的代理api,总是出现各种问题。搜索接口基本不能用。
解决方案
使用puppeteer自己来爬数据了。
安装
puppeteer
npm install puppeteer --save-dev
### 或者 yarn add puppeteer --dev
不多说,直接上干货,看代码。大佬勿喷
以下是代码
index.js
const puppeteer = require('puppeteer');
const fs = require('fs');
const films = require('./a.js') //电影名的一些数据
let movieLinkArr = {}; // 爬取的Object
let filmLength = films.length // 爬取的总长度
let nowPage = 0 // 从第几页开始爬
start();
// 开始
async function start() {
if (nowPage > filmLength) return
await puppeteer.launch({
headless: false,// 关闭无图形爬取,进行真实的模拟
// 添加代理。经过爬虫实验。当我爬到1200+的时候,发现豆瓣暂时性的封了我的IP,
// 正好我有科学上网,通过自己的SSR代理,继续爬
// args: [`--proxy-server=socks5://127.0.0.1:1086`]
}).then(async browser => {
const page = await browser.newPage();
for (let i = nowPage; i < nowPage + 5; i++) {
if (i > filmLength) {
break
}
console.log(i);
await getDoubanLink(page, i);
}
nowPage += 5
fs.writeFile('db0.js', JSON.stringify(movieLinkArr), () => console.log('当前目录,文件douban.js生成成功'));
await page.close();
await browser.close();
setTimeout(() => {
start()
}, 5000);
});
}
async function getDoubanLink(page, i) {
try {
await page.goto(`https://search.douban.com/movie/subject_search?search_text=${films[i].movieName}&cat=1002`);
} catch (error) {
await page.goto(`https://search.douban.com/movie/subject_search?search_text=${films[i].movieName}&cat=1002`);
}
let src = await page.evaluate("$('.item-root img').attr('src')")
movieLinkArr[films[i].movieID] = src
}
这里的
for (let i = nowPage; i < nowPage + 5; i++) {
if (i > filmLength) {
break
}
console.log(i);
await getDoubanLink(page, i);
}
nowPage += 5
这里的设定是每次爬5页,爬完存起来,等待5s再来继续爬。
是为了防止IP快速被封,我试过,不停的爬,爬了200+就被封了IP,按照代码里面爬的话我是到了1000+才被封,没空研究这个频率问题了,先用着。
这里
// 添加代理。经过爬虫实验。当我爬到1200+的时候,发现豆瓣暂时性的封了我的IP,
// 正好我有科学上网,通过自己的SSR代理,继续爬
args: [`--proxy-server=socks5://127.0.0.1:1086`]
发现豆瓣封了我的IP后,就想到通过代理来继续爬,本地有SSR,能kexue上网啥的。查看本地的SOCKS地址。
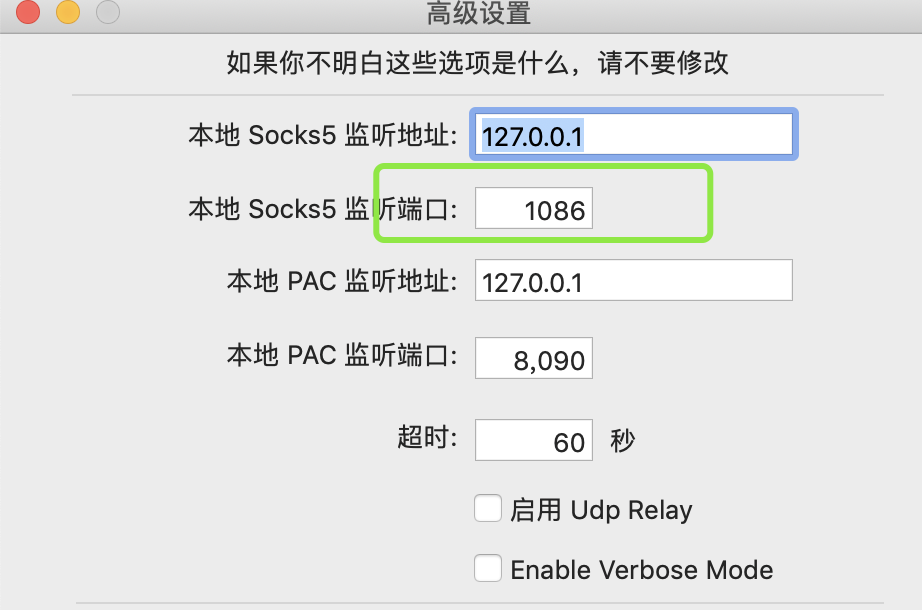
然后通过args参数设置--proxy-server
再将nowPage修改成断了的地方的index。还有fs.writeFile('db0.js',JSON.stringify(movieLinkArr),... ,将这里的db0.js 换个文件写入。比如:db[Index].js。最后再手动将这几个文件手动合并成一个就好了。
最后
node index.js
继续爬取。
结果
最后获取到了所有电影海报
{
"20191019000003": "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2551997298.webp",
"20191019000004": "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2562980418.webp",
"20191017000004": "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2539891882.webp",
"20191017000001": "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2566322897.webp",
"20191017000003": "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2525020357.webp",
"20191016000001": "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2569548689.webp",
"20191016000002": "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2544299288.webp",
"20191016000003": "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2557500825.webp",
.....
....
....
}
评论区